Entity Manager works by interpreting your configured database schema in a very particular, very opinionated way.
By way of example, this section will start with a simple data model, evolve a database schema, and show you what Entity Manager would do with it.
NoSQL databases do not offer the schema & query abstractions enjoyed by RDBMS developers, so any NoSQL database schema will be intrinsically platform-specific. This example will evolve a database schema for the DynamoDB platform, but the presented design process should work equally well against any NoSQL database platform.
A Microservices Application
Imagine an application that tracks the credit card transactions of its users.
When a User performs a Credit Card or online shopping cart Transaction, the application rounds the Transaction amount to the nearest dollar and credits that amount to a Beneficiary chosen by the User. Online shopping cart Transactions can be related to the User by Credit Card and Email, so each User can have more than one Email, which must be unique in the system. Users also sign up with an Email, so there’s a particularly close relationship between Users and Emails.
FYI this example is actually a small slice of the real VeteranCrowd application, which uses Entity Manager’s previous JS version in production!
Here’s a breakdown of the entities & relationships in the system. We’re building a microservices back end, so each entity will live on a specific service as indicated:
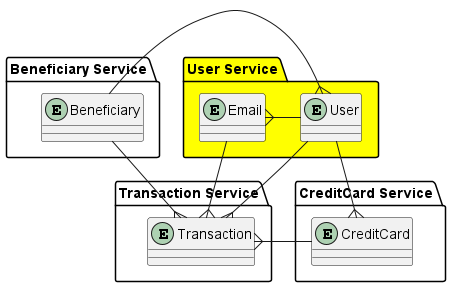
For this example, we’re going to focus on the requirements of the User service.
User Service Data Model
Let’s focus narrowly on the User service data model. We need to account for:
- the User and Email entities and their properties, and
- cases when either entity is the many side of a one-to-many relationship.
Every entity has to have a unique identifier that doesn’t change. If there isn’t a natural fit with an existing entity property, we’ll use a nanoid.
Here’s the resulting data model (see the entity notes below for more info):
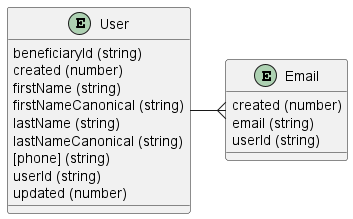
User Entity
| Property | Type | Description |
|---|---|---|
beneficiaryId |
string |
The unique id of the Beneficiary related to the User. This value is required but might change. |
created |
number |
Timestamp of record creation. This value never changes! |
firstName |
string |
User first name. |
firstNameCanonical |
string |
User first name canonicalized for search. |
lastName |
string |
User last name. |
lastNameCanonical |
string |
User last name canonicalized for search. |
[phone] |
string |
Internationalized User phone. |
userId |
string |
Unique id of User. This value never changes! |
updated |
number |
Timestamp of last record update. |
firstNameCanonical and lastNameCanonical are provided to support searching for Users by name. Canonicalizing a name converts it to a consistent case and removes diacritical marks and non-word characters. So Gómez-Juárez-Álvarez becomes gomezjuarezalvarez.
Why doesn’t Entity Manager perform canonicalization internally? All Entity Manager data transformations are reversible to support safe data migration. Canonicalization throws away data, so your application should perform any canonicalization before sending data to Entity Manager.
Email Entity
| Property | Type | Description |
|---|---|---|
created |
number |
Timestamp of record creation. |
email |
string |
Email address. Unique by definition and never changes, so we can use this value as the record’s unique id. |
userId |
string |
Unique id of related User. |
An Email record has no updated property because no property on the Email record is subject to change.
Single Table Design
The primary job of a table in a relational database is to support schema & query abstraction. Tables are intended to map cleanly to data entities, and it is the database engine’s job to organize the physical distribution of data to support efficient query operations.
To be highly available, data must be in one physical location.
In a DynamoDB database (as with any NoSQL database) there is no such abstraction layer. Consequently, it is the developer’s job to organize the physical distribution of data to support efficient query operations.
In order to be physically “close” to one another in any meaningful sense, related DynamoDB records must be stored in the same table. This is the origin of the single-table design pattern.
Entity Manager takes a highly opinionated approach to this pattern. We’ll start from the assumption that all User and Email entities must live on the same table, and the following sections will explain the design constraints at work in DynamoDB and how to implement a table design that Entity Manager can support.
Keys, Indexes & Queries
A record in a DynamoDB table is uniquely identified by its primary key. This can take one of two forms, chosen at design time:
-
a simple primary key is a single property that uniquely identifies the record. In DynamoDB-land, this is called the partition key. In more general NoSQL terms, this is a hash key.
-
a composite primary key is a combination of two properties that uniquely identify the record. In DynamoDB-land, these are the partition key and the sort key. In more general NoSQL terms, these are respectively a hash key and a range key.
For reasons that will become clear below, Entity Manager requires a composite primary key for all data entities. To keep this discussion as general as possible, we’ll refer to its components as the hash key and the range key.
All high-performance NoSQL databases (including DynamoDB) make a clear distinction between two very different kinds of data retrieval operations:
-
Scan operations read every record in a table. At scale, finding an individual record with a scan is very slow and very expensive. Scans are to be avoided whenever possible.
-
Query operations read an ordered subset of records in a table. At scale, finding an individual record with a query is very fast and very cheap. Queries are the preferred way to access data in a NoSQL database.
In DynamoDB and other NoSQL databases, whatever else may be true, queries obey one hard rule: a query can only be performed on records with the same hash key!
A query is performed on an index of the table. An index is a copy of the original table, in which:
-
records are partitioned by their hash key values, and
-
within each hash key partition, records are sorted by their range key values, and
-
record properties not relevant to the index are left out.
We will discuss secondary indexes in the next section, but for now understand that a table’s most fundamental index is the table itself: its hash and sort keys are defined at table creation, and new records are added to the table in hash and range key order.
In a query:
-
The hash key is fixed, so the return set is limited to records with a hash key value equal to the query’s hash key parameter.
-
Within the constraints set by the hash key parameter, records are quickly compared to range key constraints to find records with range key values that are equal to, greater than, less than, or between the query’s range key parameters.
The most fundamental kind of query retrieves a single record of a given entity type by its unique identifier. Our table design must support this kind of query, therefore:
-
A record’s hash key must identify its entity type, and
-
A record’s range key must contain its unique identifier.
If you examine the User and Email entities in our data model, you’ll see that there is no property on either that identifies the entity type. We will need to create this property.
Also, while each entity has a unique identifier, these exist on different properties. DynamoDB expects to find a range key on the same property of every record. We will therefore need to create a new property for the range key as well.
Leaving out other properties, here’s what two such records might look like. The gear icon indicates a generated property:
| ⚙️ | Property | User Record | Email Record |
|---|---|---|---|
email |
'me@karmanivero.us' |
||
| ⚙️ | hashKey |
'user' |
'email' |
| ⚙️ | rangeKey |
'userId#wf5yU_5f63gqauSOLpP5O' |
'email#me@karmanivero.us' |
userId |
'wf5yU_5f63gqauSOLpP5O' |
'wf5yU_5f63gqauSOLpP5O' |
Note that the generated rangeKey property value contains the unique property name as well as its value! This is an important Entity Manager feature that enables the safe construction of composite keys and super-efficient query at scale. More on this to come!
Secondary Indexes
In the previous section we constructed a table model with a built-in index that allows us to query the User service table for a single User or Email record by its unique identifier.
This is a good start, but here are a few other obvious cases we might need to support:
- Find all User records created in the last 30 days.
- Find all User record whose first name starts with “J”.
- Find all Email records for a given User.
- Find all User records for a given Beneficiary.
Remember that DynamoDB has physically organized our User service table data according to our primary key design. If we want to write a query that uses a different property as its hash or range key, we need to create a secondary index.
The technical details of secondary indexes are beyond the scope of this document but are easily accessible for your data platform. The sections below will focus on the relevant record properties and how Entity Manager interacts with them.
Simple Range Key Index
A secondary index can be thought of as an automatically-maintained copy of its parent table that uses a different property for its hash key, its range key, or both.
If we’d like to find a list of Users created in the past 30 days, then we need an index that can:
- differentiate by entity type, and
- sort by creation date.
We could use the same argument to find users whose records were recently updated. And while we’re at it, we’d also like to be able to find a User by a piece of his phone number!
Here’s what the required indexes might look like:
| Index | Entities | Index Component | Record Property |
|---|---|---|---|
created |
Email & User | Hash Key | hashKey |
| Range Key | created |
||
phone |
User | Hash Key | hashKey |
| Range Key | phone |
||
updated |
User | Hash Key | hashKey |
| Range Key | updated |
These indexes require us to generate no new properties beyond what we created above, and have the added advantage of allowing us to find Email records by creation date as well (remember, the Email entity has no phone or updated properties).
Composite Range Key Index
Our next task is to create an index that lets us query User records by the first letter of firstName. This is a bit more complex.
Recall that every query implicitly includes a sort as well. How would we like our result set to be sorted?
Naively, we might consider an index like this:
| Index | Entities | Index Component | Record Property |
|---|---|---|---|
firstName |
User | Hash Key | hashKey |
| Range Key | firstNameCanonical |
The problem with this approach is that, while the result set will be sorted by first name, all of the “John” records will appear in an effectively random order. Intuitively, we’d like those to appear in a useful order as well, say by lastNameCanonical.
To achieve this, we need to create a new property that combines firstNameCanonical and lastNameCanonical in a way that allows us to query by firstNameCanonical and sort by lastNameCanonical. Also, while we are at it, it probably makes sense to be able to do the same thing on the basis of lastNameCanonical.
Finally, as our system scales into millions of users, we will probably have more than one “John Smith” in the database. In these cases, it still makes sense to have some kind of rational sort, even if we won’t be likely to search on it. So let’s sort by created or updated in case of a tie.
Here are our sample records from above, with the relevant properties added:
| ⚙️ | Property | User Record | Email Record |
|---|---|---|---|
created |
1726880933 |
1726880947 |
|
email |
'me@karmanivero.us' |
||
firstName |
'Jason' |
||
firstNameCanonical |
'jason' |
||
| ⚙️ | firstNameRangeKey |
'firstNameCanonical#jason | lastNameCanonical#williscroft | created#1726880933' |
|
| ⚙️ | hashKey |
'user' |
'email' |
lastName |
'Williscroft' |
||
lastNameCanonical |
'williscroft' |
||
| ⚙️ | lastNameRangeKey |
'lastNameCanonical#williscroft | firstNameCanonical#jason | created#1726880933' |
|
[phone] |
'17739999999' |
||
| ⚙️ | rangeKey |
'userId#wf5yU_5f63gqauSOLpP5O' |
'email#me@karmanivero.us' |
userId |
'wf5yU_5f63gqauSOLpP5O' |
'wf5yU_5f63gqauSOLpP5O' |
|
updated |
1726880933 |
A couple of key points:
-
I added some spacing in the range key values above to make them a little easier to read. In practice, Entity Manager concatenates these values without spaces!
-
While the
createdproperty is a number, the generatedfirstNameRangeKeyandlastNameRangeKeyproperties are necessarily strings! Entity Manager configures all generated properties as strings, but configures their non-string components so they sort correctly within the composite value. More on this in another section!
Here’s the full set of indexes our table now supports:
| Index | Entities | Index Component | Record Property |
|---|---|---|---|
created |
Email & User | Hash Key | hashKey |
| Range Key | created |
||
firstName |
User | Hash Key | hashKey |
| Range Key | firstNameRangeKey |
||
lastName |
User | Hash Key | hashKey |
| Range Key | lastNameRangeKey |
||
phone |
User | Hash Key | hashKey |
| Range Key | phone |
||
updated |
User | Hash Key | hashKey |
| Range Key | updated |
Alternate Hash Key Index
To find all email records for a given User, we have a couple of choices. Here’s one:
| Index | Entities | Index Component | Record Property |
|---|---|---|---|
user |
Hash Key | hashKey |
|
| Range Key | userId |
If my query specifies a hash key of email a range constraint of equal to 'wf5yU_5f63gqauSOLpP5O', then my query will indeed return all email records for the User with userId equal to 'wf5yU_5f63gqauSOLpP5O'. But there are a couple of problems with this approach:
-
The range key values are a nanoid: effectively a random string. This will allow me to find a match, but the resulting sort order is not likely to be useful.
-
The range key constraint is operating against all emails in the system. A different choice of hash key would narrow this down and give us better performance.
Instead, let’s try this:
| Index | Entities | Index Component | Record Property |
|---|---|---|---|
userCreated |
Hash Key | userId |
|
| Range Key | created |
Setting these index hash keys to userId has significantly limited the record set any range key constraint is applied against. In fact, to satisfy the our test case (finding the Emails of a given User), we don’t need a range key constraint at all! The indexes will simply sort our records in a useful way, meaning by the Email record’s created timestamp.
Why didn’t we create a userUpdated index as well? Because, since there is nothing to change on an Email record, we didn’t give it a updated property. So the index would be useless!
Note that we didn’t need to create any new generated properties to support this case.
External Hash Key Index
Our final case was to find all User records for a given Beneficiary, sorted either by created or updated.
On one hand, this is interesting because beneficiaryId is a property of the Beneficiary entity, which lives on another service.
On the other hand, this should feel familiar: just as with userId above, we can use the hash keys on our new indexes to constrain the result sets down to just the User records we’re interested in.
Here’s the index:
| Index | Entities | Index Component | Record Property |
|---|---|---|---|
beneficiaryCreated |
User | Hash Key | beneficiaryId |
| Range Key | created |
||
beneficiaryUpdated |
User | Hash Key | beneficiaryId |
| Range Key | updated |
This indexes support:
-
Finding the oldest or most- or least-recently created or updated User records for a given Beneficiary.
-
Displaying a Beneficiary’s Users in the order they were created or updated.
While we’re at it, though, consider that a Beneficiary Manager will likely also want to sort and search related Users by name, and perhaps locate them by phone number. So let’s add these indexes as well:
| Index | Entities | Index Component | Record Property |
|---|---|---|---|
beneficiaryFirstName |
User | Hash Key | beneficiaryId |
| Range Key | firstNameRangeKey |
||
beneficiaryLastName |
User | Hash Key | beneficiaryId |
| Range Key | lastNameRangeKey |
||
beneficiaryPhone |
User | Hash Key | beneficiaryId |
| Range Key | phone |
Rounding Out Index Requirements
Here’s a recap of our table structure so far with generated properties:
| ⚙️ | Property | User Record | Email Record |
|---|---|---|---|
beneficiaryId |
'JCcwi4vyqwMJdaBwbjLG3' |
||
created |
1726880933 |
1726880947 |
|
email |
'me@karmanivero.us' |
||
firstName |
'Jason' |
||
firstNameCanonical |
jason |
||
| ⚙️ | firstNameRangeKey |
'firstNameCanonical#jason | lastNameCanonical#williscroft | created#1726880933' |
|
| ⚙️ | hashKey |
'user' |
'email' |
lastName |
'Williscroft' |
||
lastNameCanonical |
'williscroft' |
||
| ⚙️ | lastNameRangeKey |
'lastNameCanonical#williscroft | firstNameCanonical#jason | created#1726880933' |
|
[phone] |
'17739999999' |
||
| ⚙️ | rangeKey |
'userId#wf5yU_5f63gqauSOLpP5O' |
'email#me@karmanivero.us' |
updated |
1726880933 |
||
userId |
'wf5yU_5f63gqauSOLpP5O' |
'wf5yU_5f63gqauSOLpP5O' |
Here’s a consolidated list of the resulting indexes:
| Index | Entities | Index Component | Record Property |
|---|---|---|---|
beneficiaryCreated |
User | Hash Key | beneficiaryId |
| Range Key | created |
||
beneficiaryFirstName |
User | Hash Key | beneficiaryId |
| Range Key | firstNameRangeKey |
||
beneficiaryLastName |
User | Hash Key | beneficiaryId |
| Range Key | lastNameRangeKey |
||
beneficiaryPhone |
User | Hash Key | beneficiaryId |
| Range Key | phone |
||
beneficiaryUpdated |
User | Hash Key | beneficiaryId |
| Range Key | updated |
||
created |
Email & User | Hash Key | hashKey |
| Range Key | created |
||
firstName |
User | Hash Key | hashKey |
| Range Key | firstNameRangeKey |
||
lastName |
User | Hash Key | hashKey |
| Range Key | lastNameRangeKey |
||
phone |
User | Hash Key | hashKey |
| Range Key | phone |
||
updated |
User | Hash Key | hashKey |
| Range Key | updated |
||
userCreated |
Hash Key | userId |
|
| Range Key | created |
One thing we haven’t discussed yet is projection. Once your query has applied hash & range key constraints, you may wish to filter the result set by additional properties. These properties will need to be included in the index.
We’ll address this in a later section.
Partition Limits
So far we have ignored a major issue related to scale.
In Keys, Indexes & Queries above we observed that a NoSQL table or index always partitions data by its hash key value. We also pointed out that any query is always constrained to a single hash key value, also known as a data partition. These observations drove the index design process above.
Here’s the issue: in a real-world NoSQL database, there is a limit to the maximum size of a data partition!
In DynamoDB, the maximum size of a data partition is 10 GB. In the presence of a Local Secondary Index (LSI), this imposes a hard limit on the amount of data that can be indexed by a single hash key value. Without an LSI, hash key values can cross partition lines, but you will still pay a performance penalty for doing so.
Even if your specific database design theoretically permits infinite partition size, it’s a good practice to keep partition sizes under control.
Here’s a breakdown of the storage requirements so far for our example User record:
| ⚙️ | Property | User Record | Bytes |
|---|---|---|---|
beneficiaryId |
'JCcwi4vyqwMJdaBwbjLG3' |
21 | |
created |
1726880933 |
8 | |
firstName |
'Jason' |
5 | |
firstNameCanonical |
'jason' |
5 | |
| ⚙️ | firstNameRangeKey |
'firstNameCanonical#jason | lastNameCanonical#williscroft | created#1726880933' |
49 |
| ⚙️ | hashKey |
'user' |
4 |
lastName |
'Williscroft' |
11 | |
lastNameCanonical |
'williscroft' |
11 | |
| ⚙️ | lastNameRangeKey |
'lastNameCanonical#williscroft | firstNameCanonical#jason | created#1726880933' |
49 |
| ⚙️ | rangeKey |
'userId#wf5yU_5f63gqauSOLpP5O' |
28 |
phone |
'17739999999' |
11 | |
updated |
1726880933 |
8 | |
userId |
'wf5yU_5f63gqauSOLpP5O' |
21 | |
| Total | 231 |
Let’s nearly double this to 512 bytes (0.5 KB) per record, to account for name & phone variations and the addition of a few new User properties and indexes. With this record size, we can fit 20 million User records into the single partition defined by a hashKey value of user.
Keep in mind that our sample User record is very small! The maximum size of a DynamoDB record is 400 KB. If your records approach this size, you only have room for 25,000 records in each data partition!
By contrast, Facebook has around 3 billion users! So if Facebook were implemented on DynamoDB with a similar User record size, it would need at least 150 partitions to store all of its User records!
How would this work?
The answer: create a shard key.
Shard Keys
We’ve already established that a data partition is defined by a unique hash key value on a table or an index. To shard the hash key means to give it a slightly different value on different records.
For example:
| ⚙️ | Property | User Record 1 | User Record 2 |
|---|---|---|---|
| ⚙️ | hashKey |
'user!1' |
'user!2' |
Now, as long as we are careful about assigning shard keys '1' and '2' to the underlying hash key, we can have as many User records as we like without exceeding the partition size limit!
Unfortunately, we’ve also introduced some new problems:
-
How do we know which shard key to assign to a given User record?
-
How do we apply the shard key to alternate hash keys?
-
We can only query a single sharded hash key at a time. So how can our application efficiently search User records across all shard keys?
Deterministic Sharding
As presented above, the shard key is really a component of the hash key. And the value of a record’s hash key is fixed: it must be present at record creation, and it can’t change over the life of the record!
So the shard key must be determined at the time of record creation. It must also be drawn from a limited set of possible values, since each unique shard key value produces an additional data partition that must be queried in parallel to search across all partitions.
Entity Manager solves this problem by applying a hash function to the record’s unique identifier (in this case userId or email), and constraining the output to a limited set of possible values.
So in this example, given an appropriate Entity Manager configuration, a userId value of 'wf5yU_5f63gqauSOLpP5O' will always produce a hashKey value of 'user!1', and a userId value of 'SUv7FfJDUsWOmfQg2wp7o' will always produce a hashKey value of 'user!2'.
More on this in a later section!
Alternate Hash Keys
In Secondary Indexes above we created the following indexes that use an alternate User property (marked with 👈) as the index hash key:
| Index | Entities | Index Component | Record Property |
|---|---|---|---|
beneficiaryCreated |
User | Hash Key | beneficiaryId 👈 |
| Range Key | created |
||
beneficiaryFirstName |
User | Hash Key | beneficiaryId 👈 |
| Range Key | firstNameRangeKey |
||
beneficiaryLastName |
User | Hash Key | beneficiaryId 👈 |
| Range Key | lastNameRangeKey |
||
beneficiaryPhone |
User | Hash Key | beneficiaryId 👈 |
| Range Key | phone |
||
beneficiaryUpdated |
User | Hash Key | beneficiaryId 👈 |
| Range Key | updated |
||
userCreated |
Hash Key | userId 👈 |
|
| Range Key | created |
But since the records in these indexes have approximately the same cardinality as the User table itself, they also need to be sharded!
Every indexed record contains a copy of the record’s primary key, so even an index like beneficiaryCreated that does not reference userId directly will still contain that property and can be sharded on the basis of its value.
We can therefore update our generated fields and index definitions to account for sharding across of all indexes on the User service table.
Here’s the updated set of User service table properties. I’ve marked the new and updated hash key properties with a 👉:
| ⚙️ | Property | User Record | Email Record | |
|---|---|---|---|---|
beneficiaryId |
'JCcwi4vyqwMJdaBwbjLG3' |
|||
created |
1726880933 |
1726880947 |
||
email |
'me@karmanivero.us' |
|||
firstName |
'Jason' |
|||
firstNameCanonical |
jason |
|||
| ⚙️ | firstNameRangeKey |
'firstNameCanonical#jason | lastNameCanonical#williscroft | created#1726880933' |
||
| ⚙️ 👉 |
hashKey |
'user!1' |
'email!' |
|
lastName |
'Williscroft' |
|||
lastNameCanonical |
'williscroft' |
|||
| ⚙️ | lastNameRangeKey |
'lastNameCanonical#williscroft | firstNameCanonical#jason | created#1726880933' |
||
[phone] |
'17739999999' |
|||
| ⚙️ | rangeKey |
'userId#wf5yU_5f63gqauSOLpP5O' |
'email#me@karmanivero.us' |
|
updated |
1726880933 |
|||
| ⚙️ 👉 |
userBeneficiaryHashKey |
'user!1 | beneficiaryId#JCcwi4vyqwMJdaBwbjLG3' |
||
userId |
'wf5yU_5f63gqauSOLpP5O' |
'wf5yU_5f63gqauSOLpP5O' |
||
| ⚙️ 👉 |
userHashKey |
'user!1 | userId#wf5yU_5f63gqauSOLpP5O' |
'user!1 | userId#wf5yU_5f63gqauSOLpP5O' |
Note the new value of hashKey for the Email record: 'email!'.
So far we’ve addressed sharding on the User entity. Since an Email record is so much smaller, we can fit a lot more Email records into an individual partition. So for now we are assuming that Email records are unsharded, resulting in an empty shard key.
This illustrates an important Entity Manager feature: entities in your Entity Manager configuration can be sharded independently, even though they occupy the same database table!
Here are the resulting User service table indexes, adjusted for the presence of the new alternate hash key. I marked the changes with a 👈:
| Index | Entities | Index Component | Record Property |
|---|---|---|---|
created |
Email & User | Hash Key | hashKey |
| Range Key | created |
||
firstName |
User | Hash Key | hashKey |
| Range Key | firstNameRangeKey |
||
lastName |
User | Hash Key | hashKey |
| Range Key | lastNameRangeKey |
||
phone |
User | Hash Key | hashKey |
| Range Key | phone |
||
updated |
User | Hash Key | hashKey |
| Range Key | updated |
||
userBeneficiaryCreated 👈 |
User | Hash Key | userBeneficiaryHashKey |
| Range Key | created |
||
userBeneficiaryFirstName 👈 |
User | Hash Key | userBeneficiaryHashKey |
| Range Key | firstNameRangeKey |
||
userBeneficiaryLastName 👈 |
User | Hash Key | userBeneficiaryHashKey |
| Range Key | lastNameRangeKey |
||
userBeneficiaryPhone 👈 |
User | Hash Key | userBeneficiaryHashKey |
| Range Key | phone |
||
userBeneficiaryUpdated 👈 |
User | Hash Key | userBeneficiaryHashKey |
| Range Key | updated |
||
userCreated 👈 |
Hash Key | userHashKey |
|
| Range Key | created |
Note the absence of a userPhone index. We would only want this if we needed to:
- search for user emails directly by user phone number, or
- sort user emails by user phone number.
Both of these cases feel like a step too far, so we won’t bother.
Cross-Shard Querying
We still have one significant problem left to solve: if we’ve scaled like Facebook to 150 User service table partitions, and we can only query a single partition at a time, how can we efficiently search across all partitions?
The bad news is: we CAN’T!
On a NoSQL platform like DynamoDB, a query is always constrained to a single data partition. So if we want to search across 150 partitions, we’re just going to have to run a similar-but-different query on every… single… one.
In practice, the problem is even worse! DynamoDB queries are paged, meaning that a single query returns only a limited number of records, along with a page key indicating where along the result set (which is sorted by range key) to start the next query.
So a search across 150 partitions is really a paged search across 150 partitions, where each result set is only sorted within its own partition and returns its own, independent page key.
For the sake of efficiency, you might also want to search across multiple indexes. For example, say you want to match a User record to a fragment of a name. Best to search across both the firstName and lastName indexes, eliminate any duplicates, and combine the results!
Entity Manager reduces this problem to formulating a simple query on a single shard against a single index.
Consequently, after conducting this massive parallel query, involving 150 partitions and two indexes, the developer must:
-
dedupe & sort the result set, and
-
pass the entire set of page keys to the calling process, and
-
pass the same page keys to the next query to retrieve the next page of results.
Here’s the good news: Entity Manager CAN!
With Entity Manager in place, a developer need only focus on formulating a simple query on a single shard against a single index.
Entity Manager will:
-
construct and execute throttled, parallel queries against all relevant indexes across the entire effective shard key space, and
-
dedupe & sort the result set, and
-
return the result set along with a page key map (a highly-compressed string representation of all the page keys) that can easily be passed back to Entity Manager to retrieve the next page of results.
Recap
We started with a two-entity data model including both internal and external relationships.
We then applied the single table design pattern to evolve a table and index structure that supports:
- all necessary queries on User and Email records, and
- the ability to shard User and Email records independently across multiple partitions, and
- the ability to search across all partitions and indexes in a single query.
- automated generation of all necessary properties to support the above.
Upcoming pages will dig deeply into how Entity Manager can be configured to support this model. For now, the following sections recap our design.
Data Model
Table Properties
| ⚙️ | Property | User Record | Email Record | |
|---|---|---|---|---|
beneficiaryId |
'JCcwi4vyqwMJdaBwbjLG3' |
|||
created |
1726880933 |
1726880947 |
||
email |
'me@karmanivero.us' |
|||
firstName |
'Jason' |
|||
firstNameCanonical |
'jason' |
|||
| ⚙️ | firstNameRangeKey |
'firstNameCanonical#jason | lastNameCanonical#williscroft | created#1726880933' |
||
| ⚙️ | hashKey |
'user!1' |
'email!' |
|
lastName |
'Williscroft' |
|||
lastNameCanonical |
'williscroft' |
|||
| ⚙️ | lastNameRangeKey |
'lastNameCanonical#williscroft | firstNameCanonical#jason | created#1726880933' |
||
[phone] |
'17739999999' |
|||
| ⚙️ | rangeKey |
'userId#wf5yU_5f63gqauSOLpP5O' |
'email#me@karmanivero.us' |
|
updated |
1726880933 |
|||
| ⚙️ | userBeneficiaryHashKey |
'user!1 | beneficiaryId#JCcwi4vyqwMJdaBwbjLG3' |
||
userId |
'wf5yU_5f63gqauSOLpP5O' |
'wf5yU_5f63gqauSOLpP5O' |
||
| ⚙️ | userHashKey |
'user!1 | userId#wf5yU_5f63gqauSOLpP5O' |
'user!1 | userId#wf5yU_5f63gqauSOLpP5O' |
Indexes
We will make one final adjustment here.
Recall that this database schema specifically addresses the DynamoDB platform, and that an important reason why the Entity Manager configuration supports index definition is to support the dehydration & rehydration of page keys generated by searches on those indexes.
In DynamoDB, a page key always includes the hash and range keys of the record, even if the search was performed along an index that includes neither. To support a DynamoDB implementation, therefore, the Entity Manager configuration should always include both the hash and range keys of the record in the index definition.
We will add these below where they are missing.
| Index | Entities | Index Component | Record Property |
|---|---|---|---|
created |
Email & User | Hash Key | hashKey |
| Range Key | created |
||
| Page Key | rangeKey |
||
firstName |
User | Hash Key | hashKey |
| Range Key | firstNameRangeKey |
||
| Page Key | rangeKey |
||
lastName |
User | Hash Key | hashKey |
| Range Key | lastNameRangeKey |
||
| Page Key | rangeKey |
||
phone |
User | Hash Key | hashKey |
| Range Key | phone |
||
| Page Key | rangeKey |
||
updated |
User | Hash Key | hashKey |
| Range Key | updated |
||
| Page Key | rangeKey |
||
userBeneficiaryCreated |
User | Hash Key | userBeneficiaryHashKey |
| Range Key | created |
||
| Page Key | hashKey |
||
| Page Key | rangeKey |
||
userBeneficiaryFirstName |
User | Hash Key | userBeneficiaryHashKey |
| Range Key | firstNameRangeKey |
||
| Page Key | hashKey |
||
| Page Key | rangeKey |
||
userBeneficiaryLastName |
User | Hash Key | userBeneficiaryHashKey |
| Range Key | lastNameRangeKey |
||
| Page Key | hashKey |
||
| Page Key | rangeKey |
||
userBeneficiaryPhone |
User | Hash Key | userBeneficiaryHashKey |
| Range Key | phone |
||
| Page Key | hashKey |
||
| Page Key | rangeKey |
||
userBeneficiaryUpdated |
User | Hash Key | userBeneficiaryHashKey |
| Range Key | updated |
||
| Page Key | hashKey |
||
| Page Key | rangeKey |
||
userCreated |
Hash Key | userHashKey |
|
| Range Key | created |
||
| Page Key | hashKey |
||
| Page Key | rangeKey |